
Context Engineering for Agents
How to Use Context Engineering, RAG, and Tool-Use to Build Accurate, Efficient AI Agents

Most Agentic systems fails because it lacks the right information at the right moment. Context engineering solves this by structuring and delivering exactly the information the model needs.

Context engineering is the practice of structuring and supplying information to an LLM in order to maximize its performance. Techniques such as RAG, tool use, and prompt engineering are all forms of context engineering.
LLM context
"LLM context" is an overloaded term. It can refer to -
Capacity – the maximum number of tokens the model can process at once (e.g., 128k tokens).
Content – the facts, background, and instructions given for a task.
In this article, “context” means content - the textual input that gives the model awareness of the task.

Types of context
Context to the LLMs can be provided in various forms and some of them can be categorized as system prompt, user input prompt, memory state, search and retrieval, tool use.
These can be grouped into three high-level strategies -
In-prompt context – All relevant data is embedded directly in the prompt.
Search & retrieval – Context is fetched from an external store when needed.
Tool-use – The LLM calls external tools or APIs to fetch or process information.
In-prompt context
In-prompt context refers to providing all relevant information directly in the LLM’s input prompt, such as instructions, facts, and examples, without relying on external retrieval or tools.
Large context windows (up to 1M tokens) allow huge amounts of information in a single prompt. Frontier research companies like Google, Anthropic, and OpenAI claim to have addressed the “needle in the haystack problem”, but research shows that more context can hurt performance when it contains distractors.
The truth is rarely pure and never simple (The Importance of Being Earnest)

Needle in the Haystack
“Needle in the haystack” is a metaphor for trying to find one small, important thing hidden inside a lot of other stuff. In the context of LLMs, it means:
Needle: the exact fact or sentence you want the model to recall.
Haystack: all the other surrounding text, most of which isn’t relevant.

Experiments show that adding more text to a prompt can cause Context Rot—a situation where an LLM performs no better than a simple keyword search. As the context gets longer and contains distractors, the model struggles to make complex connections and find the correct answer.
A distractor is a piece of information in the input that is related to the context but incorrect, and its presence—especially in longer contexts—can meaningfully confuse LLMs and impair their ability to identify the correct answer.
In production, avoid dumping all available data into the prompt. Instead, retrieve and insert only the context required for the current task. This reduces both cost and latency.
RAG: Scaling context with vector databases
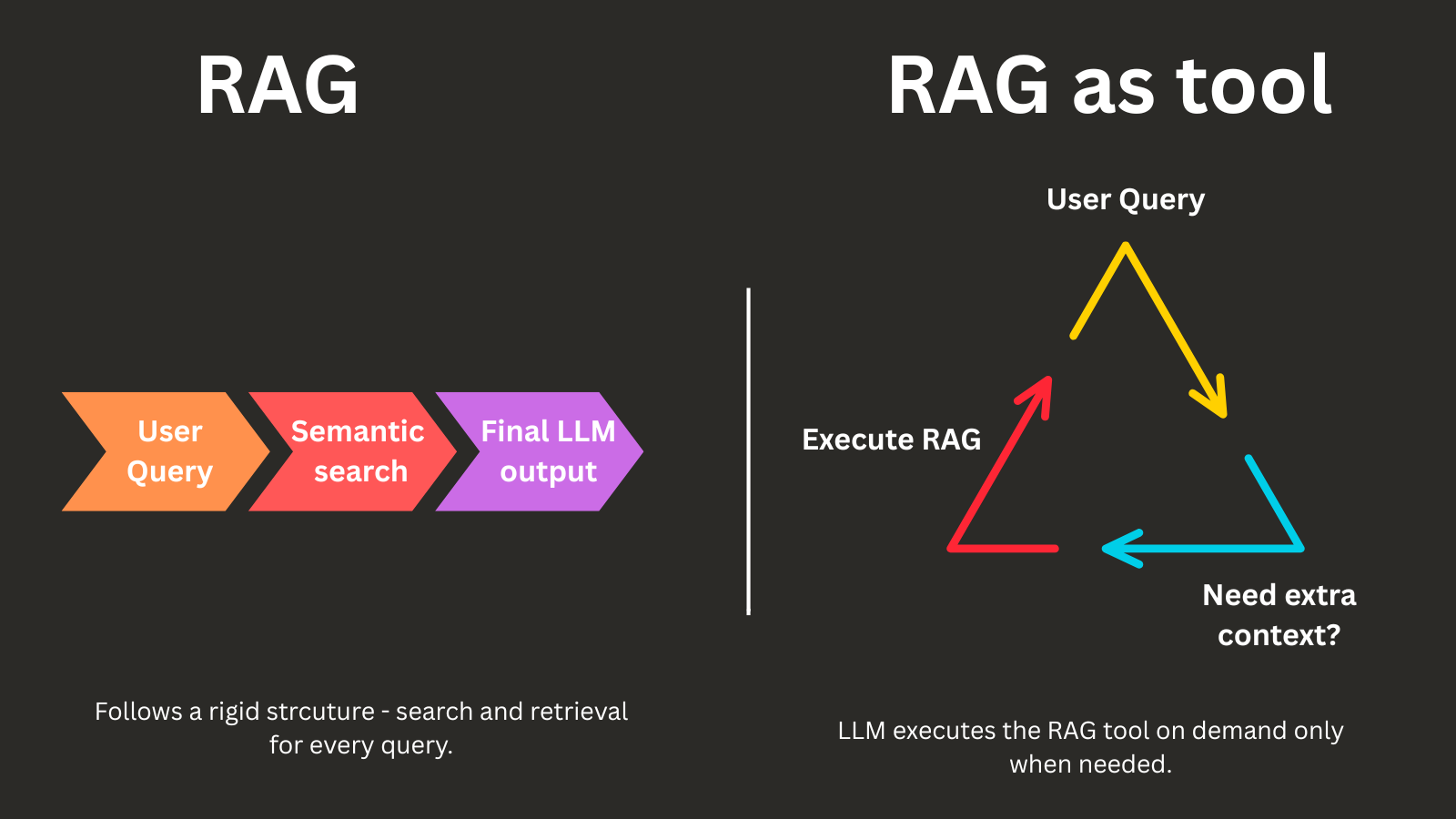
Semantic search is a popular way to find contextually aware data for a given query. It is often paired with an LLM to generate the final output based on the retrieved chunk. This process of retrieving the similar context, optionally reranking if there are multiple similar chunks, and generating the final response is called as Retrieval Augmented Generation.

Infinite scale LLM context
Semantic search data is stored in a vector database (a db which stores numerical representation of text along with metadata). With RAG, the context is offloaded to a vector database — LanceDB, Milvus, Pinecone, Qdrant — allowing virtually unlimited scale. The quality of the final output depends heavily on the quality of retrieval - embeddings, chunk size, and ranking strategy all matter.
Tool-use
Function calling or Tool-use enables LLMs to interact with the real world by executing tools (code or APIs). The tool-use output is fed back to the LLM to generate the final response.
Tool-use lets an LLM call APIs or execute code, then feed the results back into its working context. Example: a weather API call, a SQL database query, or a RAG search triggered only for relevant queries.
This makes RAG a tool the agent calls only when needed, instead of running retrieval for every query.
Conclusion
Context engineering is not about giving LLMs more information, but the right information, at the right time, in the right form. The most capable agent systems combine these methods—keeping prompts lean, retrieving at scale, and using tools on demand.